Game provider website
Nowoczesna, responsywna strona dla studia iGamingowego ZEAL, umożliwiająca prezentację gier w wersjach demo bezpośrednio na stronie. Projekt wspiera...
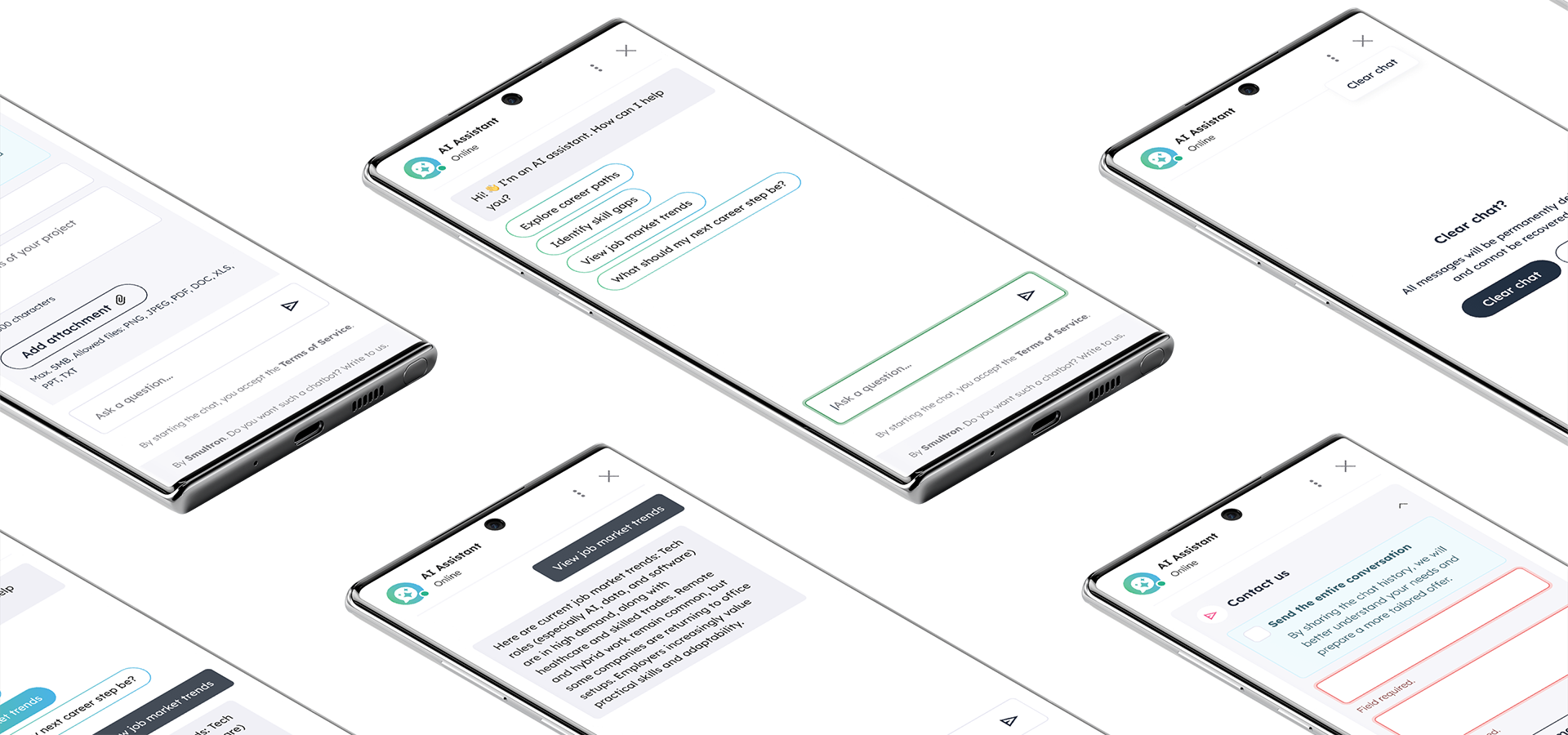
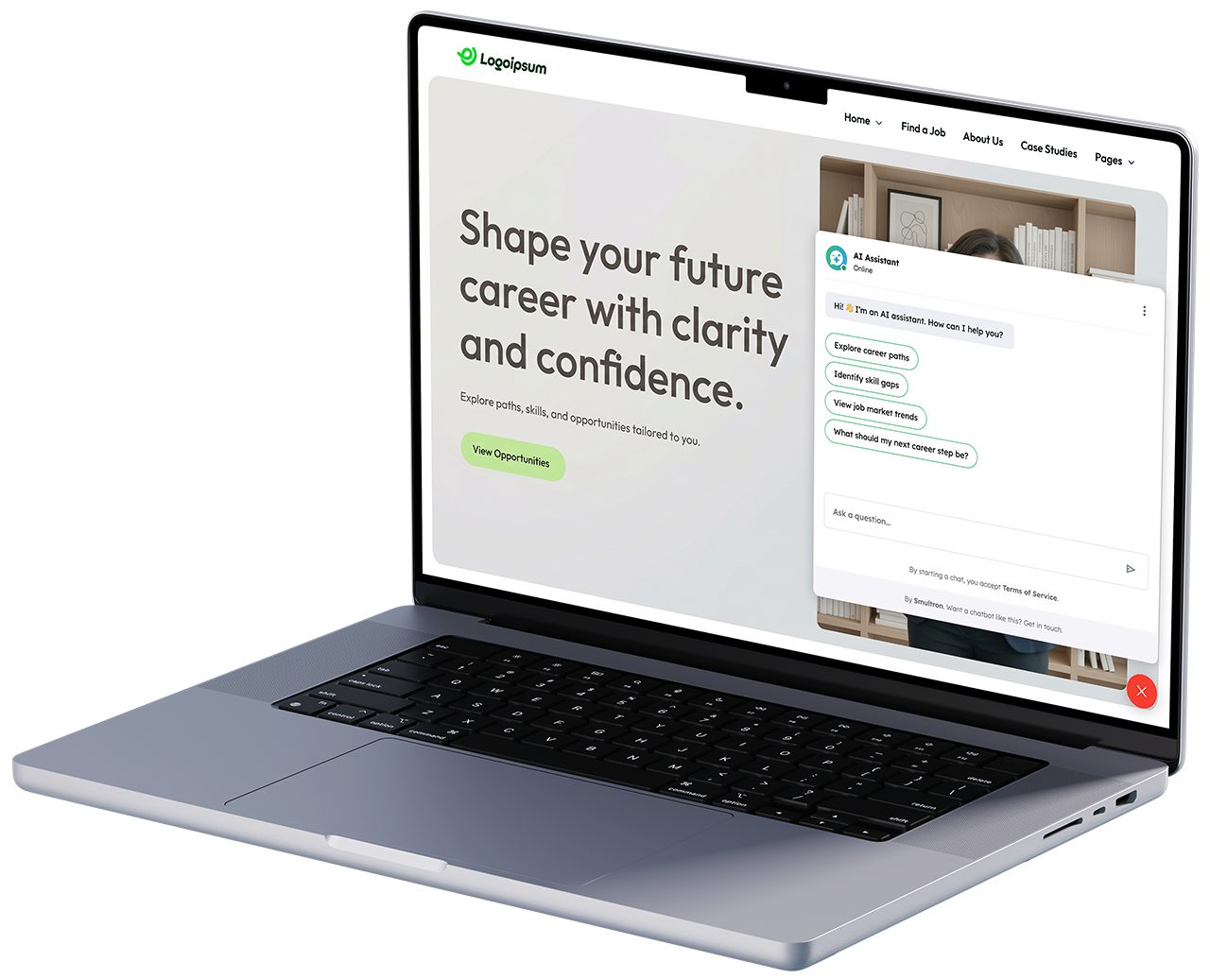
Wielojęzyczny chatbot AI działający w całości na serwerze klienta. Zewnętrzne API AI nie są używane, a dane nie opuszczają infrastruktury.
Instytucja działająca w EU potrzebowała asystenta konwersacyjnego na swoją platformę webową. Asystent miał odpowiadać na pytania użytkowników w wielu językach na podstawie dwóch źródeł danych: codziennego feedu ustrukturyzowanych rekordów z zewnętrznego API oraz biblioteki dokumentów polityk i procedur.
Głównym ograniczeniem była prywatność danych – przetwarzanie musiało odbywać się on-site, a system musiał funkcjonować w ramach ograniczonych zasobów sprzętowych. Rozwiązanie zostało zbudowane w architekturze RAG (Retrieval-Augmented Generation).
Większość dzisiejszych projektów z asystentami AI działa według tego samego schematu: wysłanie zapytania użytkownika do hostowanego API modelu językowego i odebranie odpowiedzi.
Wymagania klienta wykluczały takie podejście. Musieliśmy zbudować i uruchomić cały stos AI – model językowy, embeddingi, wyszukiwanie wektorowe, składanie kontekstu – na serwerach klienta, przy ograniczonych zasobach GPU.
Cztery ograniczenia wpłynęły na nasze decyzje techniczne.

Warstwa aplikacji
Obsługuje routing, uwierzytelnianie i zarządzanie sesjami
Platforma AI
Uruchamia modele językowe lokalnie, bez zewnętrznych wywołań sieciowych
Baza wektorowa
Przechowuje reprezentacje dokumentów i wyszukuje podobieństwa w celu pobrania kontekstu
Transport czasu rzeczywistego
Strumieniuje odpowiedzi AI na frontend, zapewniając responsywność interfejsu
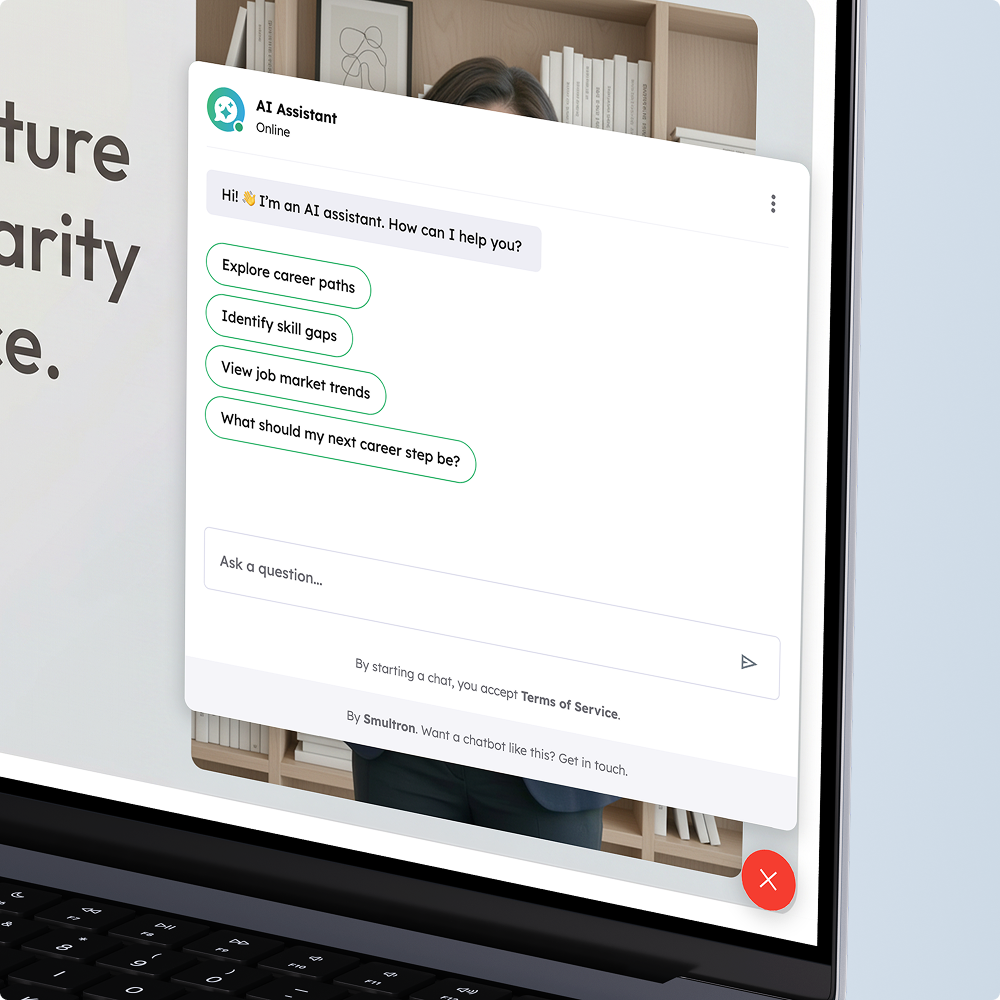
Gdy użytkownik wysyła wiadomość, najpierw przechodzi ona przez warstwę zabezpieczeń (guardrail), która sprawdza zagrożenia bezpieczeństwa.
Po walidacji wiadomość trafia do modelu językowego, który decyduje, jakich informacji potrzebuje do udzielenia odpowiedzi. W zależności od zapytania model wywołuje konkretne narzędzia retrieval – przeszukując dokumenty polityk, rekordy pracownicze lub jedno i drugie.
Wyszukiwanie działa na zasadzie podobieństwa wektorowego. Zapytanie jest embeddowane za pomocą wielojęzycznego modelu, a następnie dopasowywane do zapisanych wektorów w PostgreSQL przez podobieństwo cosinus. Wyniki można filtrować po metadanych (np. region).
Pobrany kontekst jest następnie składany w prompt razem z danymi profilu użytkownika i ostatnią historią konwersacji – wszystko skompresowane tak, by zmieścić się w budżecie tokenów modelu. Model generuje odpowiedź na podstawie tego połączonego kontekstu. Output jest streamowany do frontendu w czasie rzeczywistym przez Mercure/SSE – użytkownik widzi odpowiedź w trakcie jej pisania, zamiast czekać na pełny rezultat.
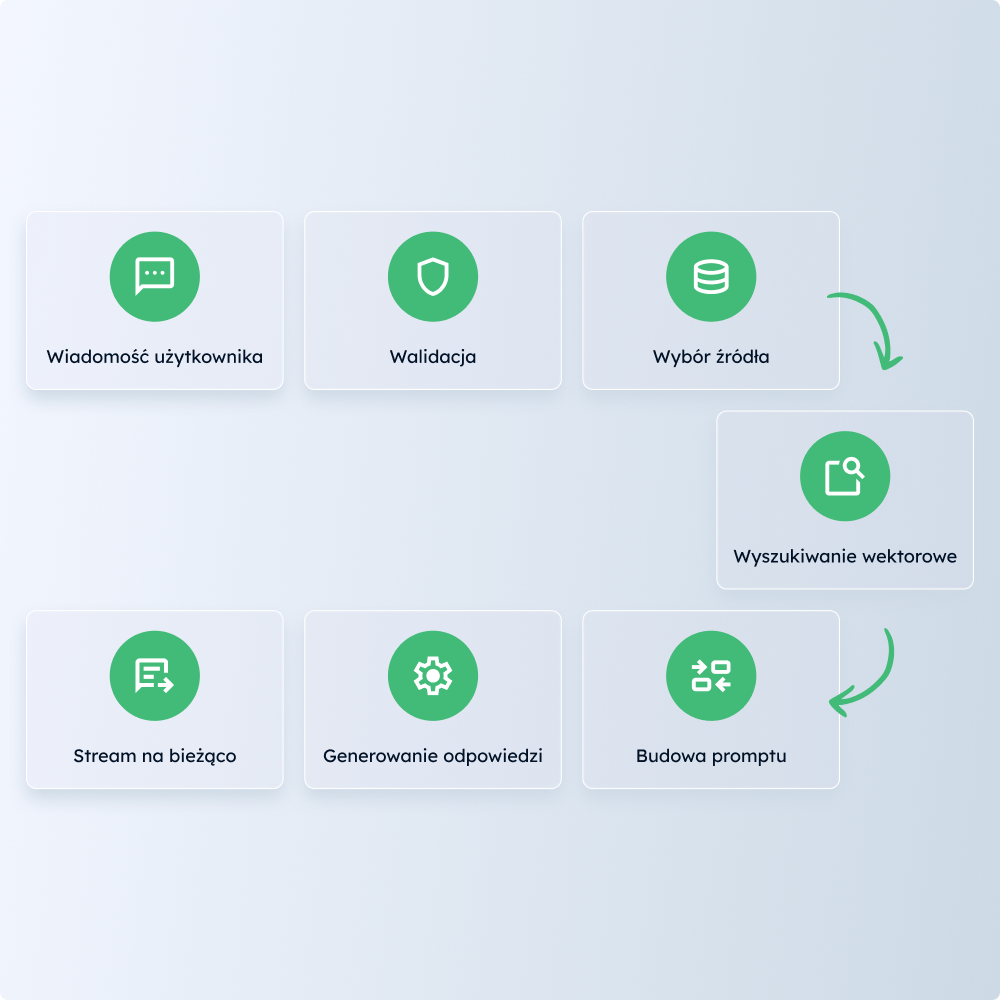
Indeksowanie dokumentów
Zautomatyzowane narzędzia do ładowania i wektoryzacji plików z politykami.
Pipeline synchronizacji rekordów
Codzienny import i czyszczenie danych z zewnętrznego API.
Narzędzia retrieval
Wyspecjalizowane funkcje wyszukiwania dostępne dla agenta AI.
Zarządzanie sesjami
Systemy obsługi profili użytkowników i historii czatów w ramach ścisłych ograniczeń.
Self-hosting asystenta AI na ograniczonym sprzęcie oznacza rozwiązywanie problemów, które hostowane API rozwiązują za Ciebie – lub całkowicie ignorują.
Bezpieczeństwo modelu, budżetowanie kontekstu, jakość embeddingów i przetwarzanie danych – wszystko to wymagało opracowania.
Każde ograniczenie kierowało nas w stronę rozwiązań trudniejszych w budowie, ale dających klientowi pełną kontrolę nad kosztami, prywatnością i zachowaniem systemu.
Wspólnie z klientem uczestniczymy w warsztatach, aby lepiej poznać jego wizję i zapewnić idealne dopasowanie do oczekiwań.
Projektujemy i implementujemy wydajne oraz skalowalne bazy danych, zapewniając solidne fundamenty dla strony internetowej.

Rozpoczynamy od głębokiego zrozumienia potrzeb klienta oraz celów projektu, aby zapewnić spersonalizowane rozwiązania.

Przeprowadzamy szczegółowy audyt technologiczny, identyfikując najlepsze narzędzia i rozwiązania dostosowane do potrzeb projektu.

Tworzymy responsywne i dynamiczne interfejsy użytkownika, wykorzystując najnowsze technologie front-endowe.

Przeprowadzamy kompleksowe testy manualne, weryfikując działanie każdej funkcjonalności na różnych, dostępnych na rynku urządzeniach, zapewniając bezbłędne działanie i wysoką jakość produktu.
Wdrażamy stronę internetową na serwerze produkcyjnym, zapewniając płynny przebieg procesu oraz minimalizując ewentualne zakłócenia.

Udzielamy 12-miesięcznej gwarancji na wykonane prace, zapewniając klientowi pełne bezpieczeństwo i pewność działania strony internetowej po jej uruchomieniu.
Produkcyjny asystent RAG działający na ograniczonym prywatnym sprzęcie, przetwarzający dziennie dziesiątki tysięcy rekordów, obsługujący wielojęzyczne zapytania ze współdzielonej przestrzeni wektorowej – przy zerowym wypływie danych poza infrastrukturę i zerowych kosztach per token.