Ink'n'art e-commerce
Our team of JavaScript and PHP developers has created comprehensive e-commerce application that offers professional-quality 3D packaging designs....

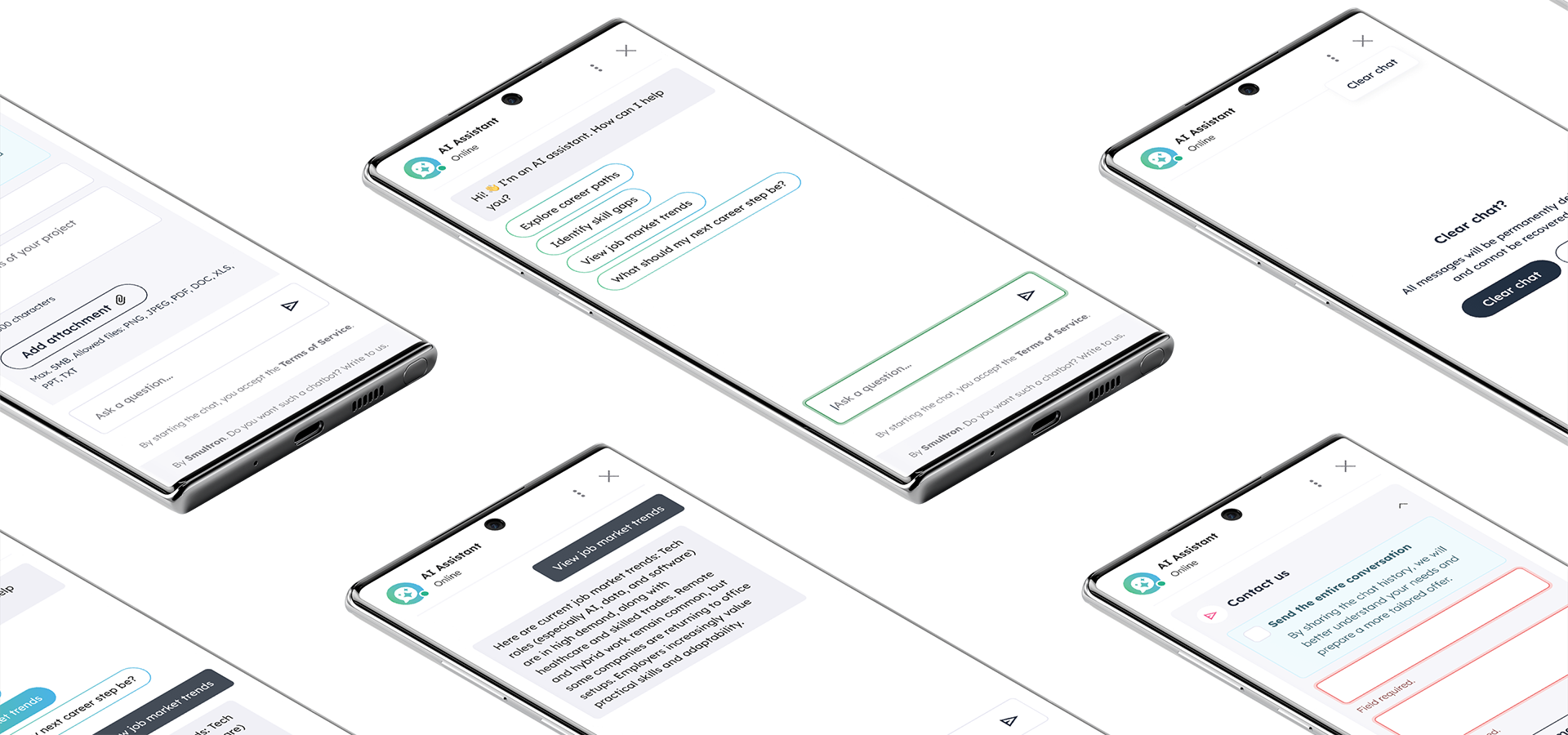
A multilingual AI chatbot running entirely on the client’s servers. No data ever leaves the infrastructure and no external AI APIs are used.
An international enterprise client required a conversational assistant supporting career planning and professional decision-making. The assistant had to answer user questions in multiple languages based on two data sources: a daily feed of structured records from an external API and a library of policy documents.
The assistant had to answer user questions in multiple languages based on two data sources: a daily feed of structured records from an external API and a library of policy documents.
The primary constraint was data privacy: all processing had to stay on-site and the system had to function within limited hardware resources. The solution was built using a RAG (Retrieval-Augmented Generation) architecture.
Most AI assistant projects today follow a similar pattern: send user queries to a hosted LLM API, get responses back.
The client’s requirements made that impossible. We needed to build and run the entire AI stack – language model, embeddings, vector search, context assembly – on the client’s own servers with limited GPU resources.
Four constraints shaped our technical decisions.

Application layer
Handles routing, authentication and session management.
AI platform
Runs the language models locally without external network calls.
Vector database
Stores document representations and performs similarity searches to retrieve context.
Real-time transport
Streams AI responses to the frontend to keep the interface responsive.
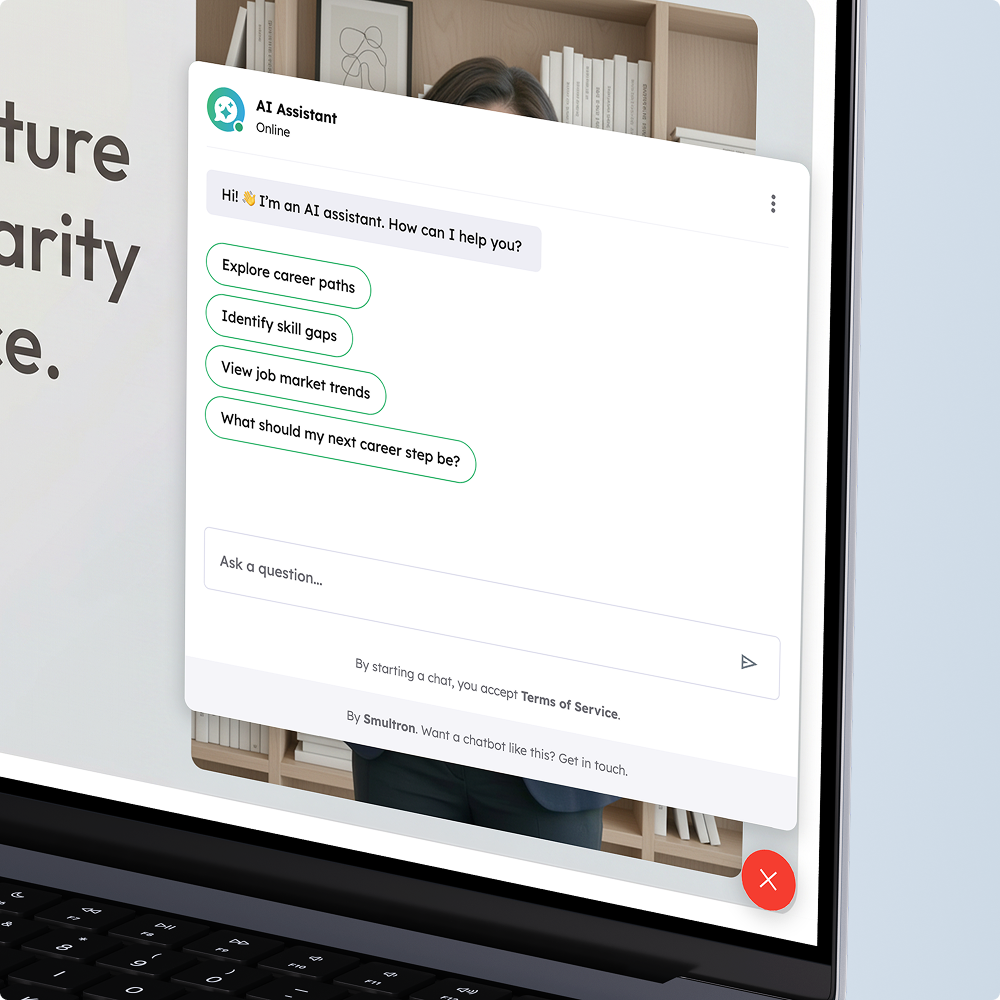
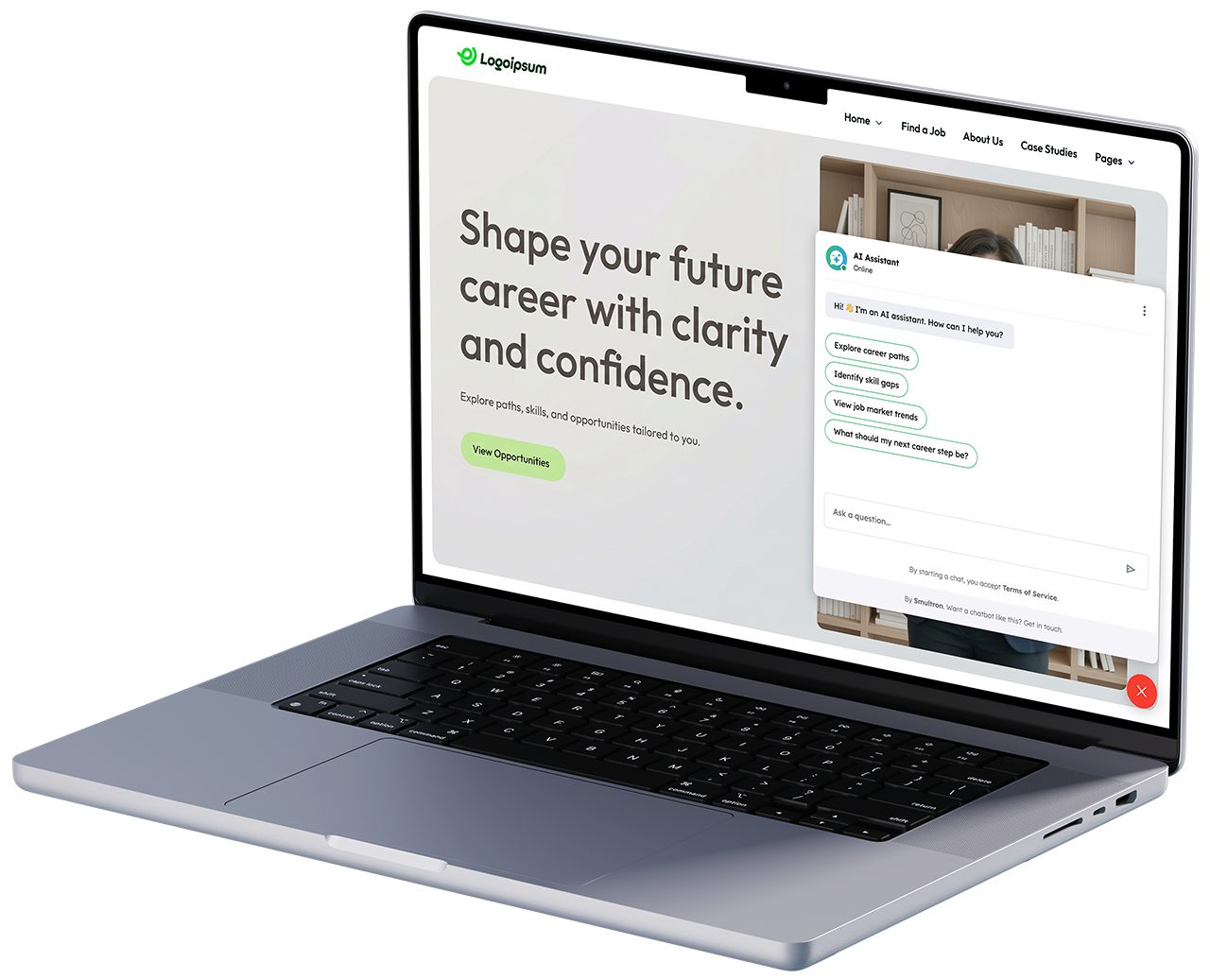
When a user sends a message, it first passes through a guardrail layer that checks for security threats before anything else happens. Once validated, the message reaches the language model, which decides what information it needs to answer. Depending on the query, the model calls specific retrieval tools – searching policy documents, job records or both.
The retrieval works through vector similarity. The query is embedded using the multilingual model, then matched against stored vectors in PostgreSQL via cosine similarity. Results can be filtered by metadata (e.g. region). The retrieved context is then assembled into a prompt together with the user’s profile data and recent conversation history – all compressed to fit within the model’s token budget.
The model generates its response based on this combined context. The output streams to the frontend in real time via Mercure/SSE, so the user sees the answer as it is being written rather than waiting for the full response.
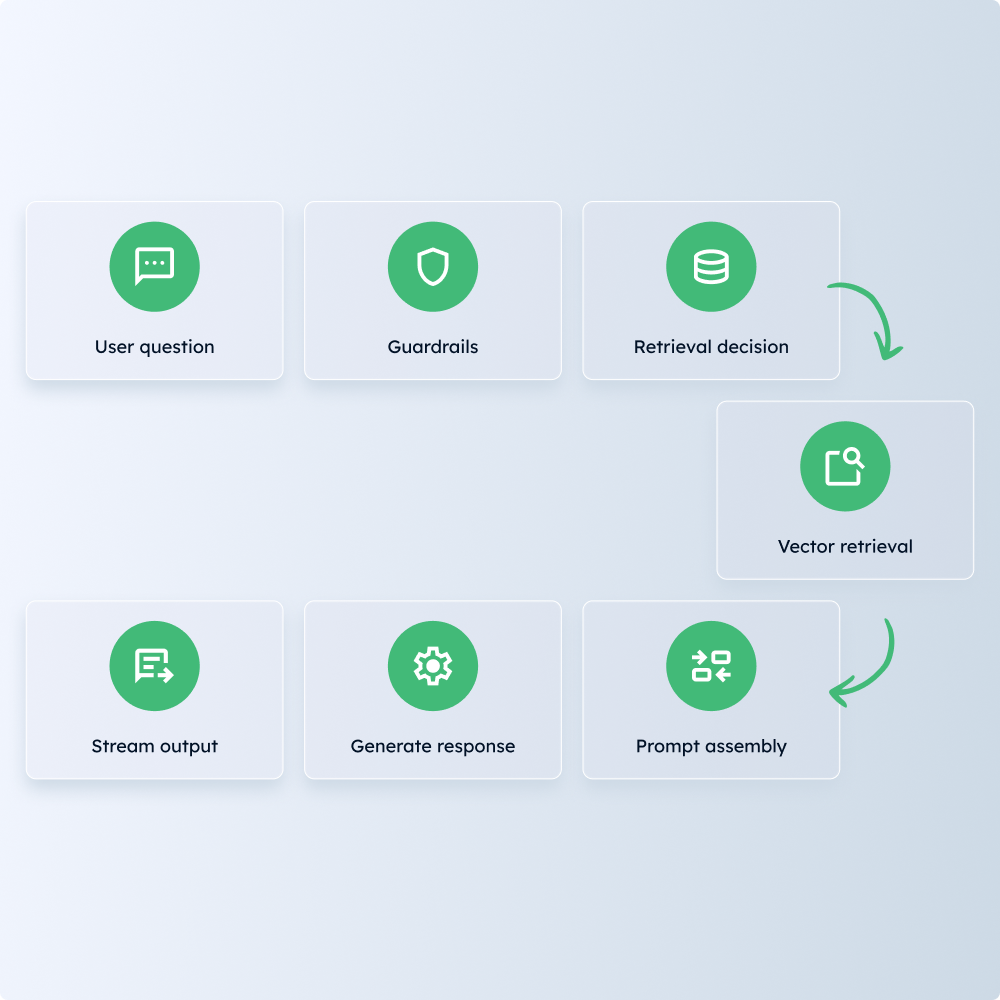
Document indexing.
Automated tools for loading and vectorizing policy files.
Record sync pipeline.
Daily import and cleaning of external API data.
Retrieval tools.
Specialized search functions available to the AI agent.
Session management.
Systems to handle user profiles and chat history within strict constraints.
Self-hosting an AI assistant on limited hardware means solving problems that hosted API solutions handle for you – or ignore entirely.
Model security, context budgeting, embedding quality and data processing all required custom engineering. Each constraint pushed us toward solutions that are more complex to build but give the client full control over cost, privacy and system behavior.
Together with the client, we participate in workshops to better understand their vision and ensure an ideal fit with their expectations.
We start by gaining a deep understanding of the client's needs and project goals to deliver personalized solutions.

We conduct a detailed technology audit, identifying the best tools and solutions tailored to the project's needs.

We create responsive and dynamic user interfaces, leveraging the latest front-end technologies.

We design and implement efficient and scalable databases, providing a robust foundation for your website.

We conduct comprehensive manual testing, verifying the functionality of each feature on various devices available on the market, ensuring flawless operation and high product quality.
We deploy the website on the production server, ensuring a smooth process and minimizing potential disruptions.

We provide a 12-month warranty on the work performed, ensuring clients complete security and confidence in the functioning of the website after its launch.
A production RAG assistant running on limited private hardware, processing tens of thousands of records daily, serving multilingual queries from a shared vector space – with zero data leaving the infrastructure and zero per-token costs.